Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Have you ever wondered how a kubernetes pod can make deploying your ai pipeline faster, smoother, and less stressful? If you’ve tried to scale machine learning models or build custom ai solutions, you already know how challenging it can be—juggling containers, managing resources, and keeping deployments reliable. That’s where kubernetes architecture comes in, giving developers a way to orchestrate and scale workloads like a pro.
In today’s fast-moving AI world, companies can’t afford slow or unreliable model deployments. An ai pipeline isn’t just about training models — it’s about versioning, reproducibility, and getting models into production with minimal downtime. This is exactly why Kubernetes has become the go-to solution for machine learning engineers and MLOps teams. By using pods as the smallest deployable units, Kubernetes allows you to package and run one or multiple containers together, making your deployments efficient and easy to manage.
And if you’re wondering what is mlflow, it’s an open-source tool that helps track experiments, package models, and manage your ML lifecycle. When paired with Kubernetes, MLflow becomes a powerful ally for tracking, scaling, and automating AI workflows from start to finish.
In this blog, we’ll explore five epic, practical tips that will help you simplify AI deployment using Kubernetes pods. You’ll learn how to organize workloads, set resource limits correctly, integrate MLflow for model tracking, and monitor everything like a pro. Whether you’re just getting started or looking to optimize production pipelines, these tips will make your deployments smoother, more cost-efficient, and easier to manage.
Ready to master the pod? Let’s dive in and make AI deployment feel less like firefighting and more like a well-oiled machine.
If you’re just getting started with Kubernetes, you might be wondering: what exactly is a kubernetes pod, and why does everyone keep talking about it? Simply put, a pod is the smallest deployable object in Kubernetes. Think of it as a wrapper around one or more containers that share the same network and storage resources. This makes it easier to manage containers as a group instead of dealing with them one by one.
Understanding pods is key to mastering kubernetes architecture. In Kubernetes, you don’t deploy containers directly—you deploy them inside pods. Each pod has its own IP address, which allows containers within the pod to talk to each other easily. This design is what makes Kubernetes so powerful for scaling workloads across nodes.
So how does this matter for AI work? Imagine you’re building an ai pipeline for a machine learning model. You might have one container for data preprocessing, another for training, and a third for inference. By putting these containers inside the same pod, they can share data quickly, which keeps your pipeline running efficiently.
For teams working on custom ai solutions, pods are essential for keeping deployments organized and reliable. They also work well with ML lifecycle tools like MLflow. If you’ve ever asked yourself what is mlflow, it’s an open-source platform that helps you track experiments and manage models—perfect for running inside Kubernetes pods.
In short, a Kubernetes pod is your starting point for deploying applications in Kubernetes. It simplifies container management, improves communication between services, and gives you the flexibility to scale your workloads as your AI needs grow.

To truly understand how your models move from code to production, it helps to look at kubernetes architecture. Kubernetes is designed to make deploying and scaling workloads simple, even when you’re running a complex ai pipeline. At its core, Kubernetes is built around a few key components: nodes, pods, and services.
A kubernetes cluster is made up of nodes—these are the machines (virtual or physical) where your workloads actually run. Inside those nodes, you’ll find pods, which are the smallest deployable objects in Kubernetes. Each kubernetes pod can hold one or more containers that share networking and storage, which is why they are perfect for custom ai solutions where you might have a training container and an inference container running side by side.
But pods can’t operate in isolation forever. This is where a kubernetes service comes in. Services act as a stable network endpoint that lets your pods talk to each other reliably, even if the underlying pods are being replaced or scaled up and down. For example, if you have a preprocessing step in your ai pipeline running in one pod and a model serving step in another, the service ensures the data flows smoothly between them without you having to hard-code IP addresses.
The beauty of kubernetes architecture is that it abstracts away the complexity of networking and scaling. This means you can focus more on training and deploying your models instead of babysitting infrastructure. You can even integrate tools like MLflow—if you’ve been wondering what is mlflow, it’s a platform that tracks experiments and versions your models—so you know exactly which model is running in which pod at any given time.
Visualizing this as a diagram often helps: imagine multiple pods connected by lines (services) forming a neat, resilient workflow that keeps your AI system running like clockwork.
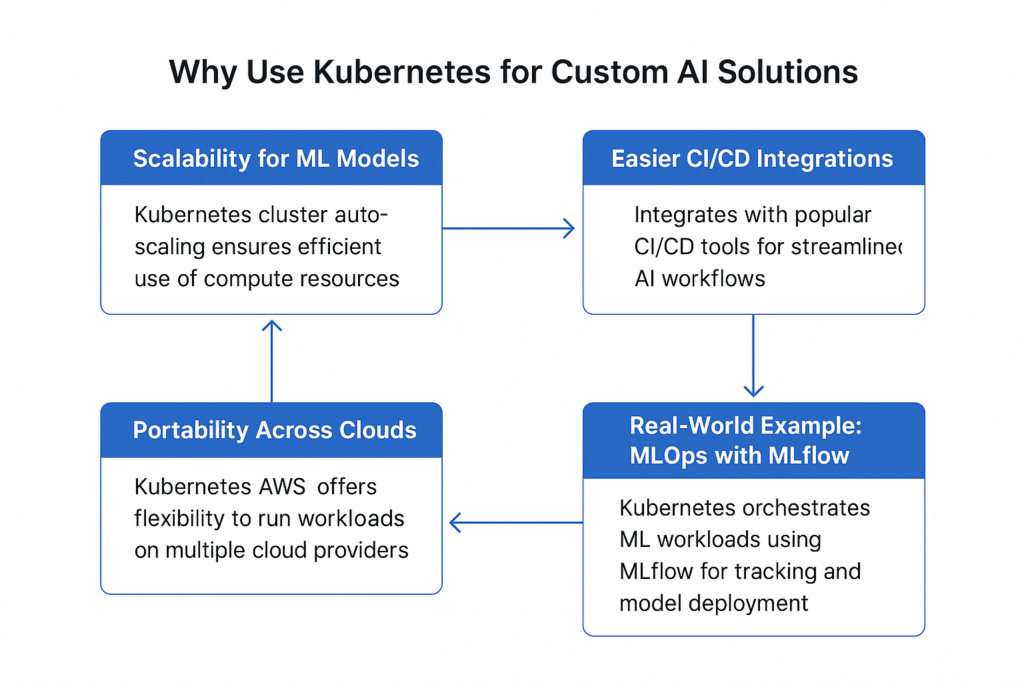
When building custom ai solutions, one of the biggest challenges is getting your models out of the lab and into production—reliably, securely, and at scale. This is where Kubernetes truly shines. By orchestrating containers inside a kubernetes cluster, it provides a rock-solid foundation for running any type of workload, including complex ai workflow setups.
AI models often require heavy compute resources, and usage can spike unpredictably. Kubernetes makes scaling simple through cluster auto-scaling, adding or removing nodes based on demand. This ensures your training jobs and inference services run efficiently without wasting resources.
Custom ai development benefits from rapid iteration, which means you need a reliable CI/CD pipeline. Kubernetes integrates beautifully with popular CI/CD tools like Jenkins, GitHub Actions, and ArgoCD. You can deploy new versions of your models with rolling updates, reducing downtime and risk.
Whether you’re using on-prem infrastructure, AWS, GCP, or Azure, Kubernetes provides a consistent way to run your workloads. In fact, kubernetes aws integration allows you to seamlessly run pods using Amazon EKS, which is great for teams that already rely on AWS services.
A common MLOps pattern involves using MLflow for experiment tracking and model registry while Kubernetes handles orchestration. You can spin up training jobs in pods, log metrics to MLflow, and automatically deploy the best model to production once tests pass. For a great step-by-step reference, check out MLflow’s official documentation to see how it pairs with Kubernetes for a full ML lifecycle.
By combining Kubernetes with MLflow, you get a production-grade system that supports continuous training, reproducibility, and scalable deployments—perfect for taking your custom AI solutions from concept to production.
Deploying an ai pipeline can seem intimidating, but Kubernetes makes it much easier when you follow some best practices. Here are five epic, battle-tested tips to streamline your workflow and get your custom ai solutions running smoothly.
When working with a kubernetes cluster, it’s easy for things to get messy if you don’t organize resources properly. Namespaces and labels are your best friends here. Think of namespaces as virtual walls that separate environments—like dev, staging, and production—within the same cluster. This way, you can safely test new features without affecting production workloads.
Labels, on the other hand, are simple key-value pairs you attach to objects. They make it easy to group related resources, query them, and apply configurations consistently. For example, you could label all components of a single ai pipeline with pipeline=training so you can find and manage them together.
Good naming conventions and labeling also make kubernetes architecture much easier to troubleshoot. When your team scales, proper organization saves time and helps avoid costly mistakes.
A kubernetes pod is powerful, but it needs the right amount of CPU and memory to run efficiently. If you don’t set resource requests and limits, Kubernetes might schedule too many pods on the same node, leading to resource contention—or too few, wasting compute.
In a kubernetes deployment, specify resources.requests for the minimum needed CPU and memory and resources.limits for the maximum the pod can use. This keeps workloads predictable and prevents noisy neighbor problems.
For ai pipeline tasks like training large models, setting limits avoids one job hogging all GPU resources and starving others. Optimizing this step can reduce cloud costs while keeping your custom ai solutions fast and reliable.
If you’ve ever asked yourself what is mlflow, it’s time to find out. MLflow is a game-changer for experiment tracking, model packaging, and deployment. Integrating it with Kubernetes brings reproducibility to your workflows.
You can run MLflow tracking servers inside pods and log hyperparameters, metrics, and artifacts as your models train. Once you identify the best model, you can register it in the MLflow Model Registry and deploy it as a REST API in Kubernetes.
This combination is perfect for teams working on multiple ai pipeline experiments in parallel. It ensures that every experiment is recorded, every model is versioned, and rollbacks are easy if something breaks. In short, MLflow + Kubernetes = reliable MLOps for custom ai solutions.
Manual deployments are slow and error-prone. Kubernetes gives you a better way through automation. Using Helm charts, you can package your kubernetes deployment as templates with predefined configurations, making it easy to spin up consistent environments.
Pair this with a CI/CD pipeline using tools like ArgoCD, GitHub Actions, or Jenkins. Every time you push code, the pipeline can build a container, update the Helm chart values, and deploy to the cluster automatically.
This approach makes deployments repeatable and reduces human error. If you’re following a kubernetes tutorial, setting up Helm and CI/CD early is one of the best ways to future-proof your workflow. Your ai pipeline updates will roll out smoothly, with zero downtime and instant rollback if needed.
Once your workloads are running, you need visibility into how they perform. Kubernetes service monitoring with Prometheus is the gold standard for metrics collection. It scrapes data from your pods, services, and nodes to provide real-time insights.
Grafana then visualizes these metrics with dashboards you can customize for your team. You can set alerts to notify you when CPU usage spikes, memory leaks occur, or a job fails. This is especially important for kubernetes jobs running time-sensitive AI training tasks.
By continuously monitoring, you can spot issues before they become outages and optimize performance proactively. Combined with other tips, this ensures your kubernetes architecture stays healthy and your custom ai solutions remain reliable.
When you combine namespaces, resource tuning, MLflow integration, CI/CD automation, and monitoring, you create a smooth, production-ready setup for your ai pipeline. These tips not only improve reliability but also save time and money. Whether you’re running workloads on-prem or with kubernetes aws, following these best practices will make your deployments future-proof.
If you’ve ever Googled kubernetes vs docker, you’re not alone — it’s one of the most common questions for developers starting their cloud-native journey. The key is to understand that Docker and Kubernetes are not competitors but complementary tools. Docker handles containerization — packaging your code, dependencies, and environment into a neat container that can run anywhere. Kubernetes, on the other hand, is about orchestration — managing and scaling those containers across a cluster.
When people talk about dockers vs kubernetes, they often mean running a single container vs running dozens of containers at scale. For example, you could deploy a single Docker container on your laptop for testing, but when it’s time to run a production ai pipeline with multiple services, you need something smarter to handle networking, scaling, and failover — that’s where kubernetes architecture comes into play.
Another common question is kubernetes vs docker swarm. Docker Swarm is Docker’s own orchestrator, and while it’s simpler to set up, Kubernetes offers more features, better community support, and works well with tools like MLflow. If you’re running custom ai solutions that need automation, rolling updates, and advanced scheduling, Kubernetes is the clear winner.
In short: Docker builds and runs containers, while Kubernetes decides where and how many to run. Together, they make deploying a kubernetes pod seamless and production-ready — exactly what you need to move from local experiments to enterprise-grade workflows.
| Feature / Aspect | Docker (Containerization) | Kubernetes (Orchestration) | Docker Swarm (Orchestration) |
|---|---|---|---|
| Primary Purpose | Builds and runs containers locally or in production | Manages and scales containers across a cluster (kubernetes pod scheduling) | Orchestrates Docker containers in a swarm cluster |
| Complexity | Simple, easy to start | More complex but highly scalable (kubernetes architecture) | Easier than Kubernetes but with fewer features |
| Scaling | Manual | Automatic cluster auto-scaling, great for ai pipeline workloads | Limited auto-scaling features |
| Networking | Basic, single-host networking | Advanced networking, service discovery, load balancing | Simple overlay network, not as flexible |
| Ecosystem & Tools | Works with any orchestrator (including Kubernetes) | Huge ecosystem: Helm, ArgoCD, Prometheus, MLflow integration | Smaller ecosystem, less community support |
| Best Use Case | Local development, testing custom ai solutions | Production-grade deployments, MLOps pipelines, hybrid cloud | Small, quick-to-deploy clusters without complex needs |
Even with the power of Kubernetes, it’s easy to run into pitfalls when setting up your deployments. Here are some common mistakes teams make — and how to avoid them.
A kubernetes pod without resource requests and limits can cause major headaches. Without them, the scheduler may overload a node or allow a single pod to hog all CPU and memory. Always define resources.requests and resources.limits to keep your workloads predictable and efficient.
Kubernetes gives you observability hooks, but you have to enable them. Skipping monitoring means you won’t know when your pods crash, restart, or slow down. Tools like Prometheus and Grafana can track metrics and send alerts so you can react quickly.
Hardcoding environment variables in your containers is a recipe for pain. Use kubernetes configmap to separate configuration from code. This makes updates easier and allows you to roll back safely if something goes wrong.
Many beginners expose services using NodePort or LoadBalancer, but forgetting to use kubernetes ingress can lead to complicated networking setups. Ingress lets you manage routes, TLS, and hostnames in one place — perfect for clean, scalable kubernetes architecture.
Avoiding these mistakes will keep your kubernetes deployment smooth, secure, and ready to scale with confidence.

Let’s put it all together with a practical example. Imagine you’re building an ai pipeline to train and deploy a machine learning model. You’ve containerized your code and are ready to run it inside a kubernetes pod. This is where Kubernetes really shines — its kubernetes architecture can schedule training jobs across your cluster, scale them as needed, and expose results through a kubernetes service.
First, you might define a simple Job to run your training step:
apiVersion: batch/v1
kind: Job
metadata:
name: train-model
namespace: ai-dev
spec:
template:
spec:
containers:
- name: trainer
image: ghcr.io/acme/ml-trainer:latest
env:
- name: MLFLOW_TRACKING_URI
value: http://mlflow-svc.ai-dev.svc.cluster.local:5000
restartPolicy: Never
This job will start a container, train a model, and log metrics to MLflow. Here’s what the Python code inside the container might look like:
import mlflow
mlflow.set_tracking_uri("http://mlflow-svc.ai-dev.svc.cluster.local:5000")
mlflow.set_experiment("churn_model")
with mlflow.start_run():
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("accuracy", 0.92)
mlflow.sklearn.log_model(model, "model")
Once the best model is registered, you can deploy it with a separate Deployment manifest and expose it via a kubernetes service for real-time inference. If demand increases, Kubernetes will scale replicas automatically.
This workflow shows how custom ai solutions can be taken from experiment to production reliably. And if you’re still asking what is mlflow, think of it as the glue that keeps track of everything while Kubernetes handles execution and scaling.
Deploying AI pipelines doesn’t have to be overwhelming. By mastering the fundamentals — starting with a kubernetes pod, understanding kubernetes architecture, and integrating tools like MLflow — you can take your custom AI solutions from concept to production with confidence. Following the five epic tips we covered — from namespaces and resource tuning to CI/CD automation and monitoring — will save you time, reduce errors, and make scaling effortless.
Kubernetes isn’t just for large enterprises; it’s a powerful ally for teams of all sizes looking to run a reliable ai pipeline. The combination of orchestration, observability, and automation gives you the ability to deliver machine learning models faster and keep them running smoothly in production.
Ready to put this into practice? Start small — try setting up a training job with MLflow inside Kubernetes, then gradually expand your workflow. As you grow, your cluster and tools will scale with you.
For more guides, templates, and expert tips on AI deployment, visit icebergaicontent.com — your hub for actionable MLOps and Kubernetes content. Together, we’ll make deploying AI feel less like firefighting and more like engineering success.




I consider, that you are mistaken. Let’s discuss. Write to me in PM.
——
https://the.hosting/hu/help/kak-ustanovit-r-v-ubuntu
https://www.bahamaslocal.com/userprofile/1/274886/ticketsburjkhalifa.html
buy uk phone number
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://www.binance.com/register?ref=IHJUI7TF